Introduction and motivation
Terraform has been the most widely adopted tool for managing cloud infrastructure for a while now, and managing EKS is no exception. The majority of companies I’ve talked to use it. However, I’ve noticed that many are at least exploring alternatives, especially in the context of managing EKS - and there are valid reasons for that.
Most of the time when you’re interacting with Kubernetes, you do so declaratively: you define the desired state (resource manifests) and rely on various controllers to update the “world” to match what’s defined. This approach is typically used to manage app configuration, deployments, networking, secrets, and more. However, when it comes to cluster configuration or application dependencies, it quickly falls short, and people resort back to good-old Terraform. Many will continue using Terraform whenever they deal with AWS API and only use Kubernetes for what “originally” belongs there. Some will identify bottlenecks and seek alternatives to improve operational efficiency or solve other problems.
You may not even realize it, but there’s a strong chance that you’ve used Kubernetes for managing some aspects of your cloud infrastructure without openly admitting it:
- You relied on EKS to create a Load Balancer when defining a service of type LoadBalancer,
- Maybe with the addition of external-dns to manage Route 53 as well,
- You used the dynamic provisioning feature of ebs-csi-driver or efs-csi-driver.
This begs the question: why couldn’t you use the same paradigm for managing the cluster itself, as well as other infrastructure?
The answer is rather simple - you can. There are tools in the market that enable this. Kubernetes at its core is already perfectly suited to be an all-in-one platform, as it’s all declarative. In this blog post, we will explore what options we have at our disposal, what their capabilities are, and what using any of these implies.
Imagine this scenario: You’re running a database in your cluster, using a Helm chart for that. Everything’s wired through Argo, just like the rest of your app deployments. You decide to switch to a managed solution (e.g., RDS), but now you have to remove that piece from Argo, move it to a separate Terraform codebase, and configure it elsewhere. Switching to a model where the application and its infrastructure are defined next to each other can drastically improve efficiency at your organization, enabling self-service for application teams and effectively offering Kubernetes as an all-in-one platform. If this resonates with you, this blog post is for you. You want to do GitOps for infrastructure. Plus, you just got into platform engineering the right way ;)
I think there’s a lot of elegance in configuring the cluster, cloud infrastructure, and applications in the same way.
I’ve mentioned Terraform because it’s the most popular tool in the market. You can replace it with Pulumi, CloudFormation, or CDK here. It doesn’t really matter, because the model is not much different.
A setup with Terraform only may look like this:
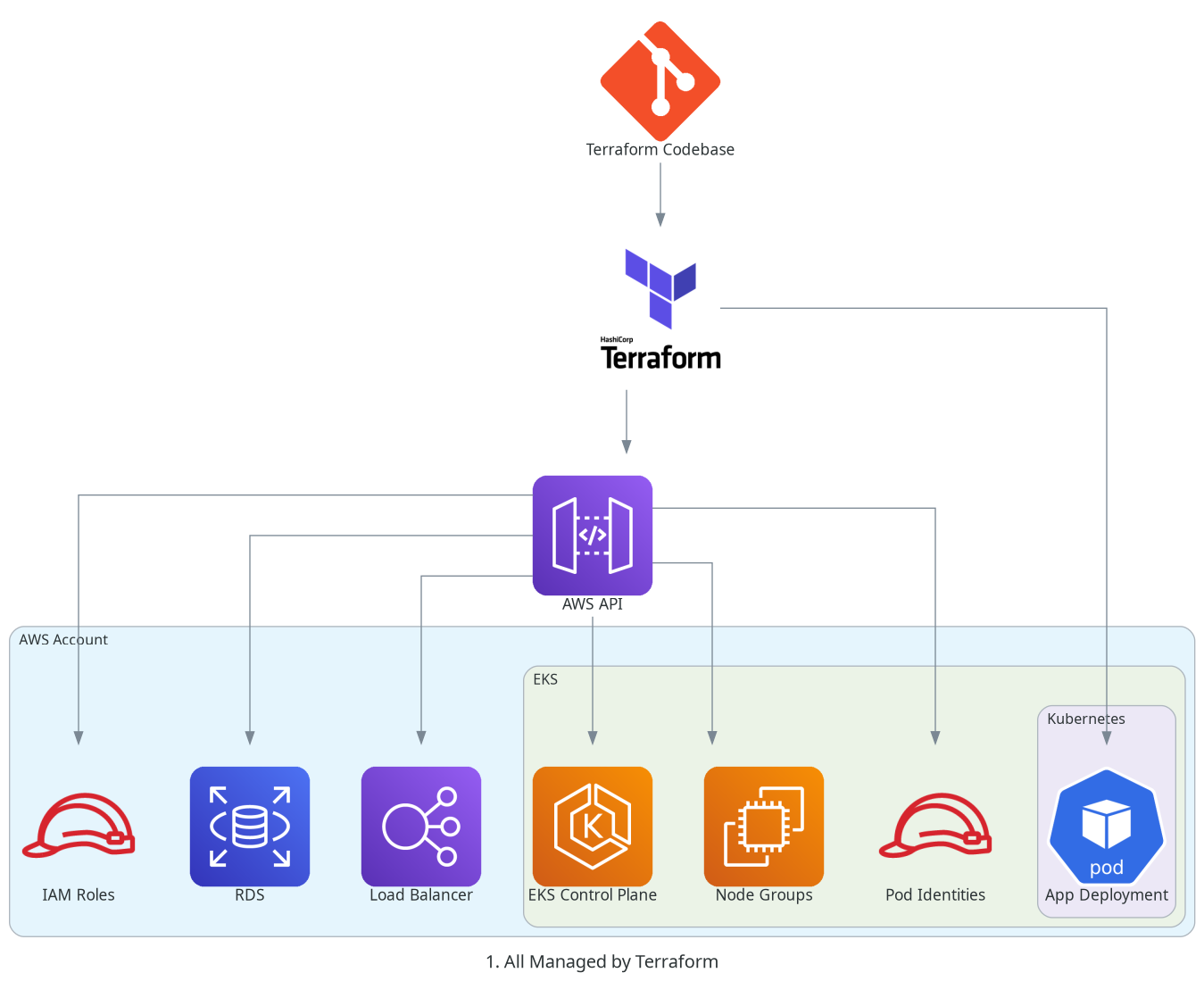
or like this, if ArgoCD is adopted for application deployments:
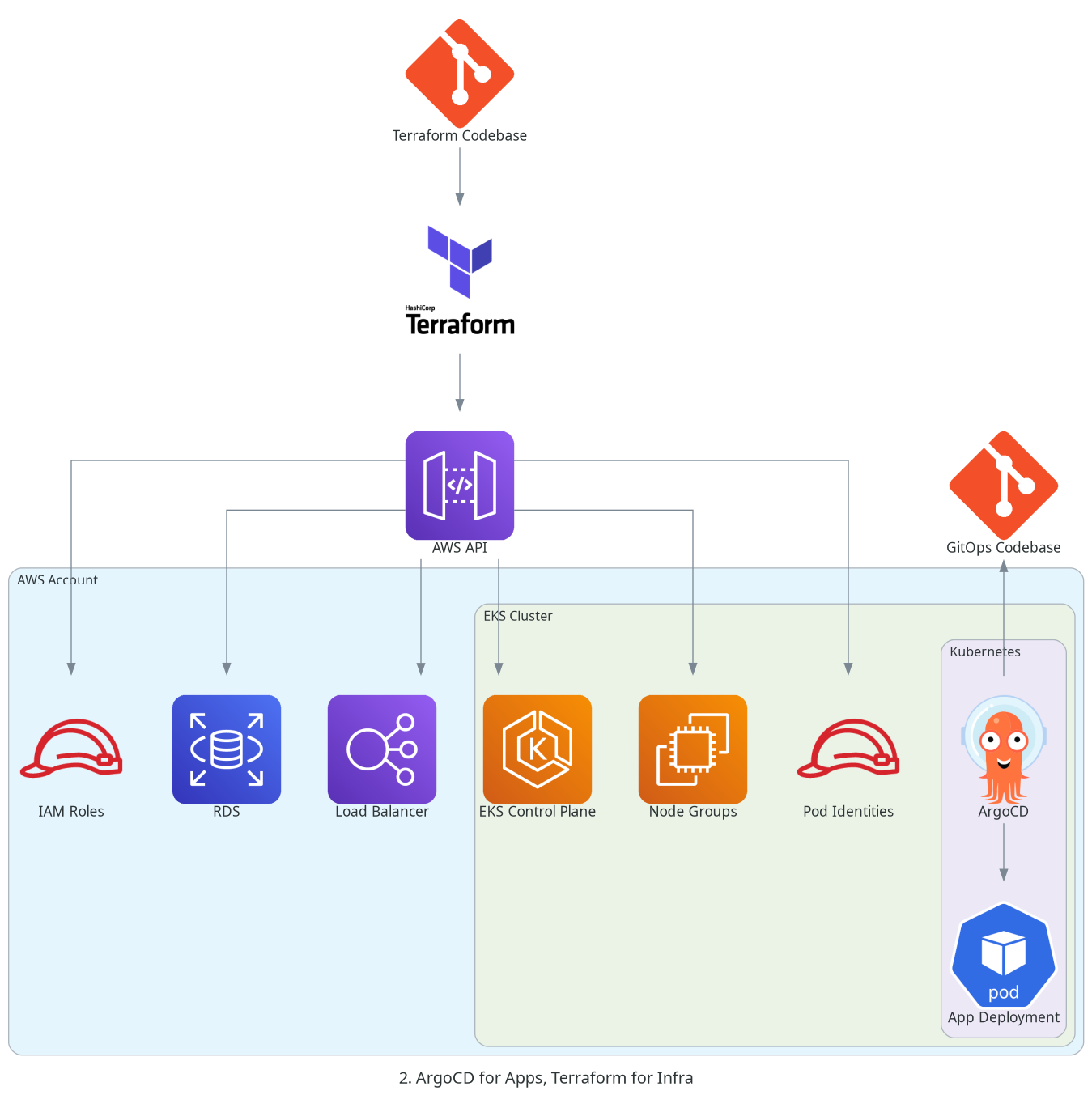
The architecture that I’d like to achieve would look more or less like this:
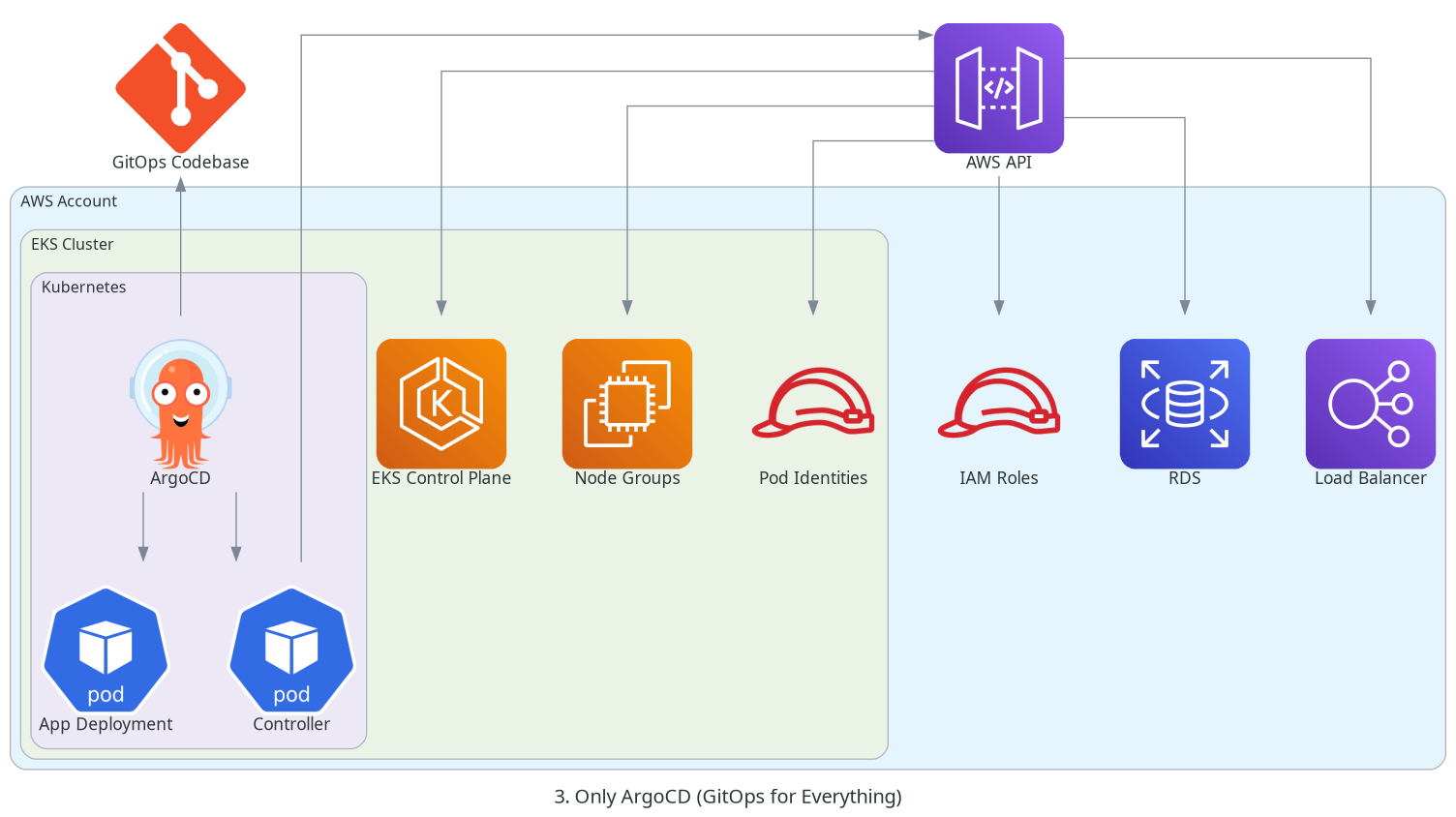
Research
Before I could start my research, I had to first narrow it down to specific resources that are the building blocks of an EKS cluster, or are required by those building blocks. To make this research feasible, I am limiting it to resources that are truly specific to a Kubernetes cluster and excluding those that can be treated as “provided” or the “foundation” of an AWS account (e.g., VPC, subnets, general networking).
Resources that I am interested in managing in a K8s-native way are:
- EKS clusters,
- EKS cluster add-ons,
- Nodes / Managed Node Groups,
- IRSA / Pod Identities.
There’s generally two types of tools that can help solve this problem:
- Tools dedicated to solving a specific problem, capable of managing a specific type of resource,
- Tools capable of managing cloud resources.
Tables below list the tools I identified for more detailed research. I am including AWS Load Balancer Controller and CSI Drivers for completeness, as I mentioned them before, but these will not be discussed in detail.
Dedicated
| Tool / Project | What it Manages | Notes |
|---|---|---|
| Karpenter | Nodes | Probably the most powerful cluster autoscaler |
| Cluster Autoscaler (CAS) | Node autoscaling | Uses EC2 ASGs, limited flexibility, uses EKS Node Groups |
| AWS Load Balancer Controller | Load Balancers | Can automatically provision ALB/NLB for Services of type LoadBalancer |
| EBS CSI Driver | EBS volume dynamic provisioning | Can automatically provision EBS volumes |
| EFS CSI Driver | EFS volume dynamic provisioning | Can automatically provision EFS volumes |
General Kubernetes-Native Infrastructure Controllers
| Tool / Project | What it Manages | Notes |
|---|---|---|
| Crossplane | AWS resources (and beyond that) | Extensible (provider system), can manage anything with an API |
| AWS Controllers for Kubernetes (ACK) | AWS resources | Manage AWS resources via Kubernetes API |
| Kubernetes Cluster API (CAPI) | Kubernetes clusters (incl. EKS) | Modular, supports managed/self-managed clusters, node groups, add-ons |
| Config Connector | GCP resources | For GCP, similar to ACK/Crossplane |
| Azure Service Operator | Azure resources | For Azure, similar to ACK/Crossplane |
Managing Nodes
There’s multiple approaches to managing EKS nodes.
- Use EKS native Node Groups,
- Cluster Autoscaler (CAS), which uses EC2 Autoscaling Groups. In my opinion, it falls short quickly, because the Node Groups must be preconfigured and it only supports a single instance type per group,
- EKS Auto Mode, which is basically an AWS-managed Karpenter (which feels quite pricy, but I digress),
- self-managed Karpenter.
All of these tools require your security groups to be preconfigured. First two options fall short quickly - you have to update your Node Group during a cluster upgrade from “outside” the cluster. Karpenter is superior to CAS in every possible way, as it lets you mix different instance types and leverage spot instances and has a powerful “drift” feature which automates patching of the nodes by performing a rolling upgrade. This also works during a control plane upgrade (as long as you’re not pinning to specific AMIs).
I’ve never used EKS Auto Mode personally. It is an option for people who want to give up a level of control for reducing the management overhead. With Auto Mode, you get an opinionated setup for nodes, load balancing, networking, storage or IAM. It uses Karpenter under the hood, but only offers a subset of its features.
I encourage you to have a look at an example of Karpenter NodePool and NodeClass definition. See https://karpenter.sh/docs/concepts/nodepools/ to learn more about configuration options in Karpenter.
Cluster Add-ons
One way to think about applications running in a Kubernetes cluster is to separate them into two groups: system components and regular apps. System components extend or enhance the platform itself, while regular apps are the workloads that benefit from those enhancements.
EKS makes it easy to manage many of these system components as cluster add-ons. These are AWS-supported integrations that can be installed and updated directly through the EKS API or console. Examples include the VPC CNI, CoreDNS, kube-proxy or storage drivers. For a full list of available EKS add-ons, check out the official documentation.
While cluster add-ons simplify managing certain components, their state lives outside of the cluster. The goal we’re pursuing here is bringing the management of these inside the cluster.
I’ve identified three tools capable of expressing EKS Add-Ons as Kubernetes objects - ACK, Crossplane or Cluster API (CAPI). ACK and Crossplane, being more general-purpose tools, can handle other aspects of cluster management - continue reading.
Another compelling alternative is self-managing these apps, as they are released as Helm charts accompanied by container images that can be managed by Argo. Addons may depend on cloud resources (e.g. IAM Roles), so these would need to be created first.
AWS provides detailed instructions on self-managing VPC CNI, Load Balancer Controller, CoreDNS or kube-proxy.
IRSA / Pod Identities
Another piece of your EKS cluster that requires configuration is the identity management for your pods, either via IRSA or Pod Identities.
Quick recap
A very short introduction to the concept of connecting Pods to IAM Roles: applications deployed to EKS may require access to AWS services, like S3 and DynamoDB. Accessing these requires authenticating with a set of credentials associated with a role with the right set of permissions. Instead of supplying these credentials from “the outside”, one can let EKS handle that for us by associating the Service Account with a specific IAM Role (see this). It’s done in a very similar way to EC2 Instance Profiles, if that is what you’re familiar with.
EKS administrators have two ways for configuring the mapping between AWS IAM and Kubernetes Service Accounts: the old IRSA (IAM Roles For Service Accounts) and the new - Pod Identities. IRSA requires you to define and attach a trust policy to the IAM Role, coupling it with cluster-specific configuration (because you have to provide a namespaced path to your service account).
Pod Identities is the “new way” (introduced in 2023) of achieving the same, just differently. A trust policy is still required, but it’s more generic and is not cluttering the role with cluster-specific configuration. The actual binding between IAM and Kubernetes Service Accounts is configured by creating a Pod Identity Association.
There’s another component required to make it work - Pod Identity Agent - that you have to install (either as a chart, or as an add-on). Pod Identity Agent comes preconfigured when using EKS Auto Mode.
The problem
The configuration is definitely much more elegant with Pod Identities compared to IRSA, because the cluster configuration is not leaking into IAM anymore and the actual mapping is configured in EKS. Unfortunately, by “EKS” I mean another AWS API here, not something residing on the cluster.
You need something talking to the AWS API to configure the associations. In the setups I worked with, that was typically done with Terraform, but here we’re looking at the alternatives. To me, that alternative would be expressing the Pod Identity Association by a CRD or be part of some configuration object provided by EKS.
Findings
I couldn’t find anything specific enabling Kubernetes-native solution.
Browsing the Internet, I stumbled upon this open GitHub ticket (Create Pod Identity Associations based on annotations on ServiceAccounts #2291) and started skimming through comments. joshuabaird suggested a solution that would meet my expectations. And so did danielloader. They mentioned two tools that I’ve been watching for a while now - AWS Controllers for Kubernetes (ACK) and Crossplane.
There’s a GKE-specific offering managed by Google - Config Connector and Azure Service Operator for AKS.
EKS Cluster
Now we get to the interesting part - managing EKS cluster with Kubernetes. We have to ask ourselves - what does it actually mean? Managing EKS resource in AWS means you have full control over cluster’s VPC, network or access configuration, as well as performing Kubernetes upgrades (upgrading control plane version). But there’s more - it also means you can create, update and delete clusters by interacting with Kubernetes API.
There’s two models you can operate in - self-managed clusters (where a certain controller responsible for this feature manages the cluster it’s running in) or a hub-and-spoke model, where a management (central) cluster controls everything around and provisions and manage additional clusters. You can also have a hybrid, where the management cluster controls itself, as well as all the clusters around it. If you want to read more about it, there’s a blog post from AWS describing an architecture with Crossplane and Flux. It’s from 2023, but the rules haven’t changed.
Findings
We have several solutions available that let you manage EKS clusters with Kubernetes. General-purpose controllers like Crossplane or ACK can manage any AWS resource.
Beyond that, there’s Kubernetes Cluster API (CAPI). CAPI uses a modular system, where hyperscalers or hypervisors are supported via providers. It supports for managed and self-managed deployments. The AWS Provider does support managed EKS and is capable of provisioning and managing clusters, Kubernetes version, managed node groups and Fargate (classed as experimental) or EKS add-ons. Sadly, Pod Identities do not seem to be supported, but it would work with IRSA.
Summary
CAPI is an interesting choice for teams opting for self-managed or hybrid clusters, but it doesn’t seem to be sufficient to fully transition to GitOps for EKS management, unless you can live with IRSA and manage your IAM roles outside of the cluster.
ACK or Crossplane are designed to talk to AWS APIs and both can fill the gap.
Further considerations
Up to this point, we only talked about cluster management, and haven’t really considered the workloads running inside, or their infrastructure needs.
IAM roles, databases, queues - you name it, the requirements vary from app to app. GitOps for Infrastructure is a powerful concept that enables a model where the application and its infrastructure are defined next to each other.
The only tools capable of doing that, out of the all we talked about in this post, are Crossplane or cloud-provider-specific like ACK.
Crossplane, with its modular design, seems to have much more potential. It can be used not only to provision an RDS instance for your app, but also to actually configure it - create the user, database and set up necessary grants (see Crossplane Provider for SQL).
Final thoughts
To wrap up, I’m not suggesting you should throw out Terraform or your existing tooling. There are plenty of good reasons to stick with what works. Maybe your organization already has a mature Terraform setup, or you’re managing a lot of non-Kubernetes infrastructure. For foundational resources like networking, VPCs, or shared services, a stable, proven-to-work approach is often the best.
But if you’re Kubernetes-heavy and are in cloud, you may be looking to streamline cloud management - especially the infrastructure closely related to your cluster and workloads inside. Another great reason to do it is if want to empower application teams to own more of their stack and employ a self-service model, Kubernetes-native tools like Crossplane and ACK are worth a serious look. They bring the familiar declarative model of Kubernetes to your infrastructure, making GitOps for infrastructure a reality.
Ultimately, it’s about picking the right tool for the job while not being afraid to explore new options when they make sense. Understand the pains of your current setup and try to assess whether adopting a specific tool can help you solve that.
What’s next?
Crossplane really got my attention. I’m going to give it a try - stay tuned as I’ll be definitely posting more about it.
If you want to learn more about it, there’s a YouTube channel, where Viktor Farcic talks a lot around Crossplane:
Thanks
Thank you for reading my blog. If you've found this post useful, please consider supporting me. ;)